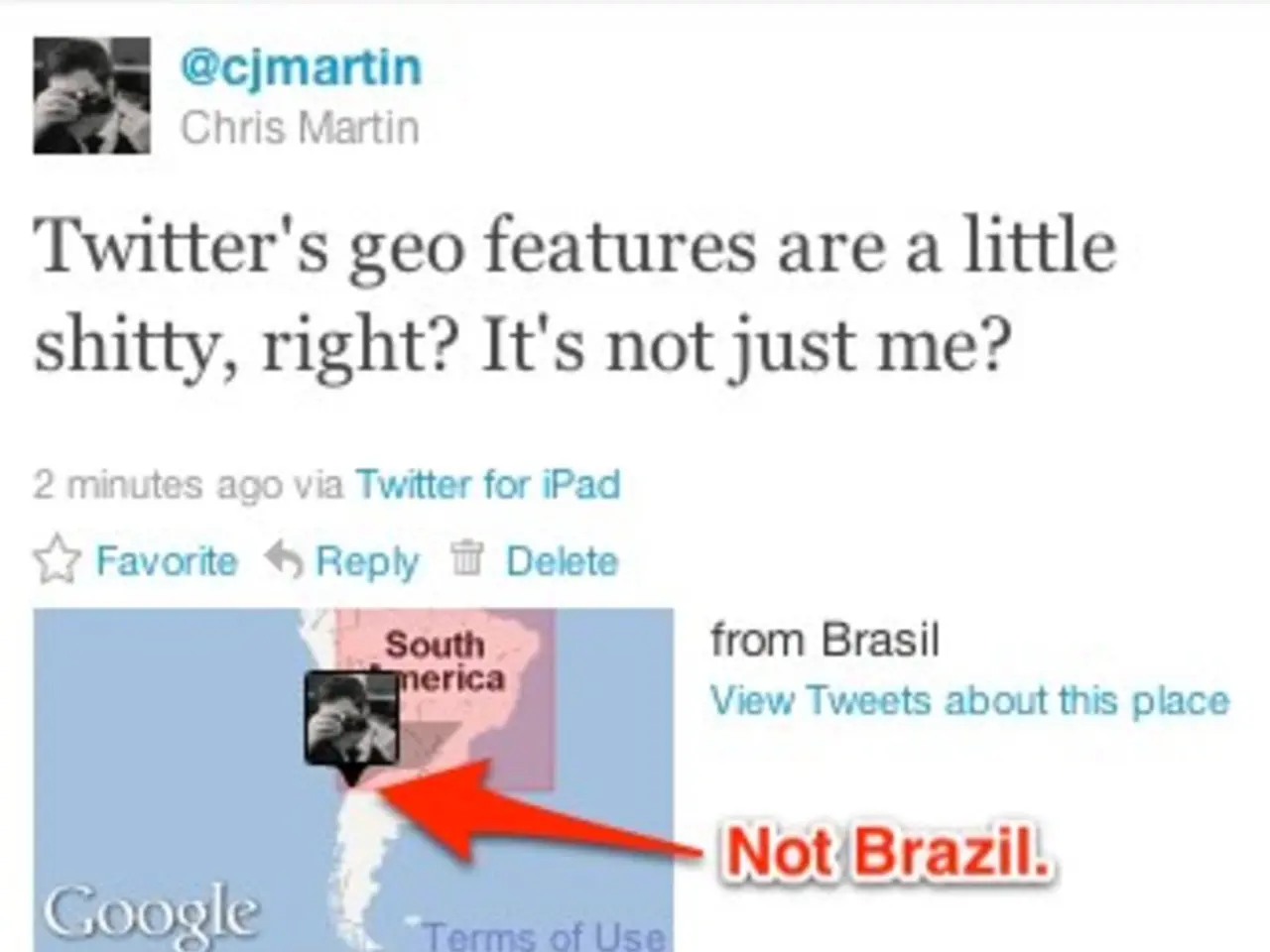
Encounter the President, William H. Brusen, hailing from the illustrious state of Onegon
In the realm of artificial intelligence, OpenAI's GPT-5 has proven itself to be a formidable force in text and code generation. However, when it comes to accurately drawing maps and timelines in images, the model falls short compared to its text-based outputs.
The primary reason for this disparity lies in the focus of GPT-5's architecture and training. While the model excels in smart text generation, coding, and reasoning, image generation, particularly precise visual image creation, is not its core focus. This is primarily handled by specialized OpenAI models like DALL-E or GPT-4o Image.
One of the key challenges in generating complex and spatially accurate images like maps or timelines using only basic shapes and math is the demand for complex spatial reasoning. When asked to create SVG drawings, which require exact placement of shapes and coordinates, GPT-5 often defaults to simpler or quicker solutions using weaker model variants, resulting in less accurate or less detailed images.
Another hurdle is the precise mathematical layout required for code-based image generation (SVG). This contrasts with text output where language patterns and factual knowledge dominate. Generating images requires translating spatial concepts into coordinates and shapes, an area where GPT-5, despite its strong coding capabilities, faces limitations.
Furthermore, the model's internal decision-making process also affects accuracy. GPT-5 chooses between fast, weaker models and slower, more deliberate "thinking" models for image tasks, which impacts image quality inconsistently. Users can prompt it to "think hard" to get better quality images, but this is not guaranteed or fully controllable.
Recent tests have shown that GPT-5 struggles with map and timeline accuracy, often using incorrect or made-up names for places and people. For instance, in a map of the United States, GPT-5 named Oregon as "Onegon," Uruguay as "Urigim," and Minnesota as "Ternia." Similarly, in a timeline of the US presidency, GPT-5 listed "Willian H. Brusen" as the fourth president, "Benlohin Barrison" in 1879, and "Henbert Bowen" in 1934.
Other AI models, such as Claude LLM and Bing Image Creator, have also shown their own set of challenges. Claude LLM was able to correctly name all state names in a map of the US but created an SVG using code instead of a PNG or JPG file. Bing Image Creator, on the other hand, failed the James Bond test by not correctly identifying the men with white hair. Moreover, Bing Image Creator referred to the United States as "United States Ameriicca" in a map of the US.
Despite these challenges, it's important to note that GPT-5 does have its strengths. For instance, when asked to bypass image generation, GPT-5 can create an accurate map of the US in code. Google's Gemini, on the other hand, created a wonderful James Bond infographic, including more than two dozen recurring stars on a timeline.
As of the latest update on Aug 8 at 2300 GMT, OpenAI has not commented on the map-drawing capabilities of GPT-5 regarding state names. The training dates for GPT-5 have also not been disclosed, but it likely predates President Trump's second term.
In conclusion, while GPT-5 excels at generating and reasoning about text and code, the model struggles with map and timeline drawings in images due to the inherently different spatial precision, visual reasoning demands, and because specialized models still handle most image generation tasks at OpenAI.
- Even though OpenAI's GPT-5 performs excellently in text and code generation, it relies on specialized models like DALL-E or GPT-4o Image for precision visual image creation, such as map and timeline drawings, due to its non-core focus on image generation.
- GPT-5's challenges in generating accurate map and timeline images are rooted in its demand for complex spatial reasoning, precise mathematical layout required for code-based image generation, and its internal decision-making process that may activate fast, weaker models instead of slower, more deliberate ones for image tasks.




{kind=link}